Contents
Current State
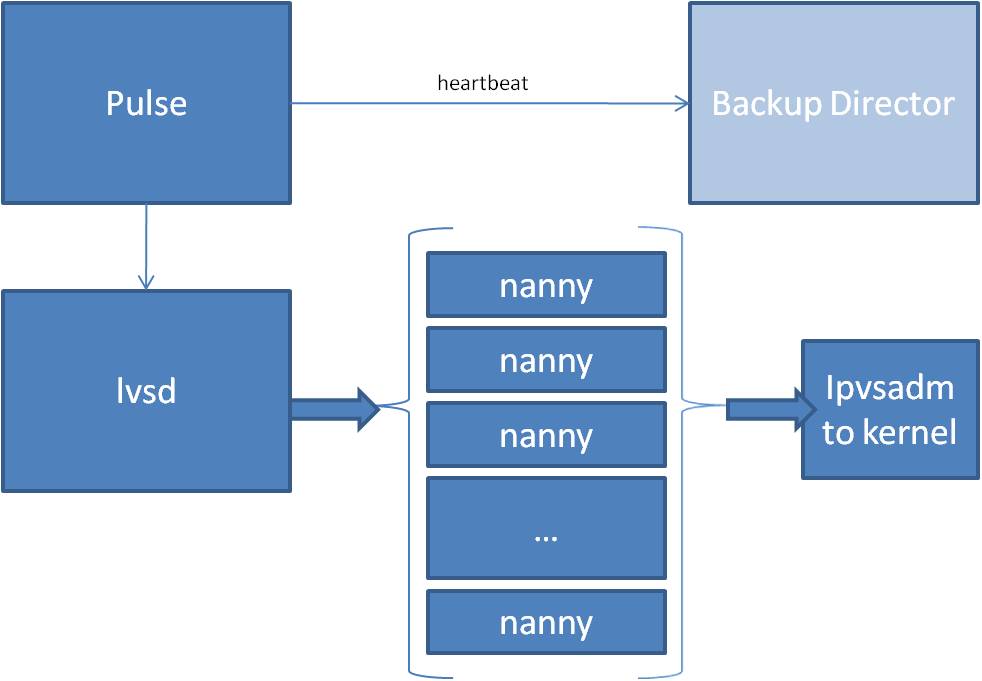
Software Block Diagram:
Piranha Gui
We do not use this in our configuration. We use in-house tools to generate lvs.cf automatically based on system configuration.
We have potentially many many vips and many port mappings, all independent of each other in overall function. They can be defined or deleted programatically at any time. We desire to NOT have 10 to 50 seconds of downtime for all (customers) being load-balanced just to add a new VIP or redefine a port mapping for an unrelated service.
Has its own rc script so you can 'service start/stop/status/restart' it.
Pulse
This daemon reads lvs.cf to find which VIPs should be brought up on the interface specified in the same file. It then use the net command to bring up those interfaces. It finds the 'other' controller in the same config file and sets up a connection with it, and periodically sends heartbeats to its partner. Failover will be initiated if the active server is determined to be inactive. Pulse also spawns an lvsd.
Has its own rc script so you can 'service stop/start/status/restart' it. restarting pulse will initiate failover immediately (the other pulse will take over services and once restart, the local pulse will be in the standby/backup mode).
This daemon has its own rc script - you can start/stop/status/conrestart/reload it.
Note that 'reload' sends a HUP signal to Pulse which attempts (at least partially) to update the running configuration without tearing down the old, still in use configurations. It in turn sends a HUP to lvsd which tries to do the same.
lvsd
This daemon can be run standalone, and/or in debug mode, but typically, in redhat boxes is run only by pulse. lvsd reads its config from lvs.conf and then invokes potentially many copies of nanny, one for each vip/service defined. It watches the state of each of its children and has a variety of rules for what to do in many different states.
It has a 'reload' HUP handler where it looks at its current configuration, compares it to the config file and either kills or invokes new nanny processes to update without teardown of other running services.
nanny
Each of these monitors a single service, and then invokes ipvsadm commands to dynamically update lvs rules in the kernel. It can do the monitoring itself, or can delegate to an external program.
Current Issues and Proposed Fixes
We use these packages in a way that is not apparently very standard as we are tripping over a variety of bugs and features that are not yet complete. We currently use non-source-code workarounds for each of these issues but are concerned that we are moving further from standard usage by doing so and setting ourselves up for future problems.
Piranha
We do not currently use Piranha - we suspect that the edge cases we have found are ones that are not hit by piranha and thus most people never see them. In other words, piranha generates only a subset of possible valid lvs.cf config files, and in particular never uses the 'reload' functionality provided by pulse and lvsd. It also appears to have some rules that prevent some obviously wrong configuration file entries (services with a timeout of 0 as an example)
Pulse
/etc/rc.d/init.d/pulse has a 'reload' function that attempts to dynamically change its config on the fly without tearing down connections. It uses a HUP signal to let Pulse know to re-examine the config.
Currently Pulse does not actually re-read its config file or adjust its list of active VIPs on the director. It does pass on a HUP to its child lvsd process. This means that if you have added a new vip to /etc/sysconfig/ha/lvs.conf, along with a port mapping that pulse will not bring the interface on line, and thus ipvsadm will not be able to add dynamic routing rules for it.
Pulse also never checks the status of its child lvsd process. If the lvsd process dies, pulse never notices and never restarts or signals it for service reload. This also has subtle issues with failover as puse may fail to properly kill lvsd (as it may have died and been manually restarted...). (note that if you have well-formed lvs.conf files and no bugs in nanny that lvsd is unlikely to ever die... but...)
We propose adding some logic to pulse to, during a 'reload', re-read the config file and to compare the currently active vips with the set in the config file and dynamically add and remove interfaces as necessary (net if....) We also want to make pulse pay attention to its child lvsd's status, potentially restarting it if the child dies, and of course logging loudly that there was a serious error.
lvsd
Lvsd has a 'reload' function that attempts to dynamically change its config on the fly without tearing down connections that do not need to be removed. It does this by comparing the current configuration with the new configuration in the conf file and killing/spawning the nanny processes needed for the change in services.
Currently there is a bug in the comparison code that makes all but the simplest cases of comparing the new to current configurations fail in unexpected ways. Essentially a couple of loop indicies appear to have been inadvertently swapped. We already have generated a patch for this which has received extensive testing and plan to submit patches back to the project team so that all may benefit.
There is also a problem (for our use anyway) in how lvsd handles the death of a child. We refer to this problem as the 'poison pill' problem. If any of lvsd's child-nanny processes die unexpectedly lvsd appears designed to tear down all port mappings and do a shutdown. This takes all load-balanced services offline, and due to the other bug described earlier in this document, is never restarted by pulse.
We believe that a better behavior for this situation would be to pay attention to the exit code of nanny (which we'll enhance also, see below) and do one of a few things. In the case that nanny exits with a 'misconfiguration' style error, we should log an error, remove the mapping from the valid set and leave all other mappings alone, running like normal, till the next reload when we might try again one time. In the case that nanny exits for some other error, we would log the error and the attempt to restart nanny. Perhaps some rate-limiting, or a maximum retry count could also be maintained.
nanny
Nanny currently has a few edge cases we've found that are obvious errors but which it currently does nothing intelligent with.
If you specify a timeout of 0 on any service nanny will start up and attempt to operate normally, but then immediately exit, tickling the poison-pill-in-lvsd bug above. Nanny could politely exit with an error-code that means 'misconfiguration' so that these types of cases as the come up can be dealt with less catastrophically.
There is a special case for the http protocol which has similar behavior if you make a port-80 mapping without a send string. Thus you can not make a simple 'tcp-connect' style mapping for port 80. We propose to change this logic so that you can have any of these behaviors.
Also we will change all exit points of the program to yield understandable return codes so that lvsd can do smarter things with it.
Additional Functionality
Because we automate the dynamically editing lvs.cf and it changes often, we would like to have the equivalent of 'service pulse reload' give good return codes that indicate everything was successful, or valid data about the type of error that caused the reload to not work.
We would like to have pulse have some kind of IPC with lvsd - either watching a domain socket, pipes, or something else that would allow pulse to know if lvsd and nanny were happy with the most recent update, or to get an error back describing at least the most recent error. (assuming one change per 'update' which is true for us as we serialize updates).
With this we could return much more debugging information to our application to help both make our application and pulse/lvsd/nanny more robust. It would help us find more pathalogical edge cases for nanny failures for instance. In the mean time, we just syslog all such errors.
Summary
We are proposing that we make several changes to parts of this package.
We would like feedback on these changes we are proposing. In particular, are any of them bad ideas because of some subtle configuration or interaction we have not thought of? If we produce patches is there a reasonable chance that they will get accepted upstream from us?
|